
These are methods for reducing the number of features (dimensions) in a dataset without sacrificing information or model performance. The goals of dimensionality reduction are used to:
- Improve the generalization, decrease runtime and decrease complexity of the model and
- Gain a better understanding of the features and their relationship to the target variable
Feature Selection #
Feature selection involves eliminating irrelevant or redundant features so that the model learns only from those features that contribute towards the target variable, eg, remove the variables “colour” and ”humidity” from a credit card fraud detection model. Feature selection generally leads to better human interpretation of the model. Some of the approaches to feature selection are outlined below.
Domain expertise: work with domain experts to identify and remove useless or low value features
Missing values: remove features with missing values greater than a certain percentage
Feature importance: remove features with importance less than a certain threshold across multiple ranking models
Low variance: remove features whose variance does not meet certain threshold, eg, removing zero-variance features removes features that have the same value in all samples
Univariate feature selection: select the best features based on univariate statistical tests such as Chi-test and F1-test
High correlation: remove features that have a correlation coefficient greater than a certain threshold; this reduces redundancy
Forward selection: add new features, one at a time, that maximize model performance to a feature set until the desired number of features or iterations is reached
Backward elimination: remove features that have the minimum impact on model performance, one at a time, from a feature set until the desired number of features or iterations is reached
Feature Extraction #
Feature extraction creates compact projections (a small number of new features) that are weighted combinations of the original features that contain the majority of the information of the full original dataset. The projections obscure any physical meaning behind the features, thus making interpretability by humans very difficult. However, they make it possible to analyze datasets that have a lot of features. Commonly used feature extraction methods are principal component analysis (PCA), linear discriminant analysis, canonical correlation analysis, and matrix factorization.
Figure 1 below illustrates the concept of principal component analysis.
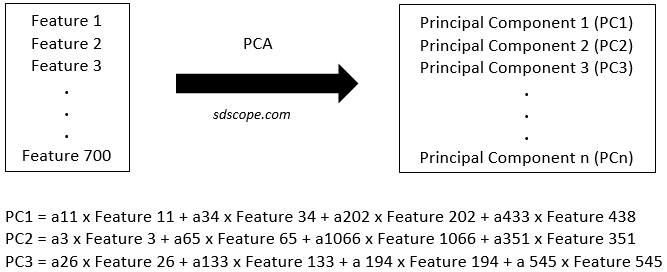
Suppose we had a dataset with 700 features. If principal components 1, 2 and 3 alone account for 96% of the variance, i.e., the information, in the dataset, then we could build the machine learning model for this problem using only these three features instead of the original 700. Notice that the principal components are complex interactions of the original features, making the resulting model very difficult to explain/interpret in terms of the original features.



