
The process for building machine learning models is exploratory and iterative in nature. It follows a lifecycle that defines the phases (or steps) spanning project discovery to completion. Using a well-defined project lifecycle greatly increases the chances of project success, ensures a comprehensive and repeatable process for building machine learning applications, and provides additional credibility to the project when the results are deployed or shared.
Successful machine learning projects take from established methodologies in data analytics and decision science such as CRoss-Industry Standard Process for Data Mining (CRISP-DM), Knowledge Discovery in Databases (KDD), Domino Data Lab’s lifecycle, Microsoft’s Team Data Science Process (TDSP), and SAS’s Sample/Explore/Modify/Model/Assess (SEMMA).
A Brief Introduction to CRISP-DM #
The CRISP-DM reference model, Figure 1, together with its derivatives is the most widely used machine learning methodology [Reference]. Its main advantages are:
- It is applicable to any use case, industry or tool,
- It tackles the machine learning process from both an application-focused and a technical perspective,
- It starts with understanding the business problem while some methodologies assume the business problem has already been formulated, and
- It is not protected by trademark, patent or copyright
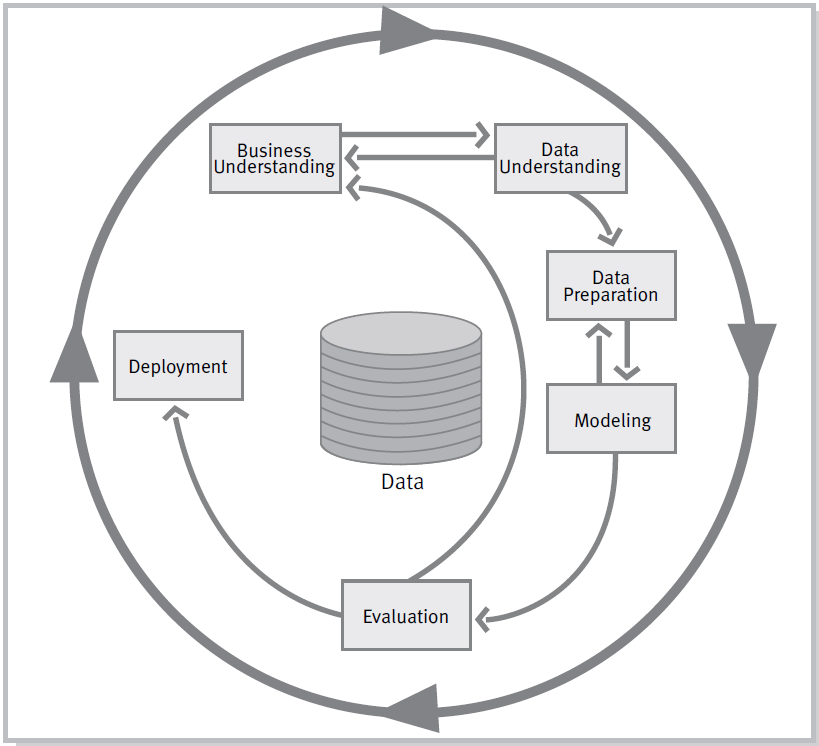
(Source: Pete Chapman, et al. CRISP-DM 1.0: Step-by-step data mining guide. Page 13. Downloaded from https://www.kde.cs.uni-kassel.de/lehre/ws2012-13/kdd/files/CRISPWP-0800.pdf)
The process consists of six phases that are not strictly performed in sequence but often require going back and forth as new insights and information are discovered. The arrows indicate the most important and frequent dependencies between phases, while the data at the center symbolizes the central role of data in the process.
Business understanding: the primary objective is to fully understand the business (or organizational) problem that needs to be addressed, for example, increasing sales, reduce compliance risk or optimize a process, and then to design a machine learning solution for it and a preliminary plan to achieve it
Data understanding: the main activities are initial data collection, becoming familiar with the data, identifying data quality problems, discovering first insights into the data, and detecting interesting subsets to form hypotheses regarding hidden information
Data preparation: constructing the final dataset from the initial raw data; includes selecting tables, records, and attributes, as well as transforming and cleaning of data for modeling tools
Modeling: selecting and applying candidate modeling techniques to data, and calibrating their parameters to optimal values, culminating in selecting one model with optimal technical performance; often requires going back to the data preparation phase to satisfy requirements of some modeling techniques
Evaluation: thoroughly evaluating the selected model to ensure it properly meet the business objectives, reviewing the steps carried out to create it, as well as ensuring all important business issues that have been sufficiently considered
Deployment: applying “live” models within customer-facing applications or in an organization’s decision-making processes; also includes model maintenance and change management
All online references accessed on 19 February 2021



