
Om Prakash, https://www.quora.com/What-are-the-key-trade-offs-between-overfitting-and-underfitting
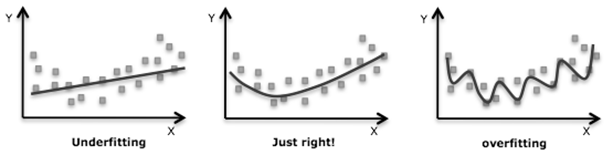
Overfitting occurs when an algorithm learns a dataset too intricately to be useful on any other dataset since no two datasets are exactly identical in the real world. An overfitted model mistakes random variations in the dataset for persistent patterns, so would yield highly accurate predictions when evaluated on training data but have a high error rate on new data. Overfitting can be reduced by:
- Regularization: adding a parameter that penalizes model complexity (fitting intricately) by artificially increasing prediction error, striking a balance between model complexity and model performance, e.g., by reducing the number of coefficients in a model
- Train/Test/Validation techniques: covered in the post Model Evaluation
- Increasing the the number of records/examples/rows in training data
- Manually reducing complexity, eg, by pruning a tree-based model
Underfitting occurs when the model is too simple to accurately capture the underlying relationships between a dataset’s features and the target variable. An underfitted model neglects significant trends in the dataset, so would perform poorly on both training data and new unseen data. Underfitting can be reduced by:
- Regularization: reducing the penalty parameter
- Adding features with more predictive power
- Algorithm: selecting a more sophisticated algorithm
An ideal model strikes a balance between capturing significant trends and ignoring minor variations in data, making it useful for making predictions in production.
Online reference was accessed on 17 July 2021



