
Supervised Learning #
A supervised machine learning model is a file generated by running an algorithm over a set of data to recognize certain types of patterns in the data. The “trained model” is then used to make predictions when presented with similar data.
The diagram and steps below illustrate a supervised learning application for predicting the selling price of a house given its features.
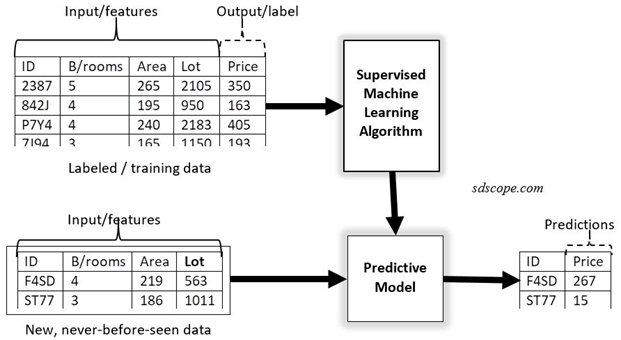
Step 1. Data containing features of houses and their selling prices (referred to as historical data) is fed into a supervised machine learning algorithm
Step 2. The algorithm analyses the data and creates a predictive model of the relationship between the features and the selling price
Step 3. The predictive model is then presented with new, never-before-seen data and infers an output based on the features in the new data
Unsupervised Learning #
Unsupervised learning does not produce a predictive model and is, therefore, not used for making predictions on new data. The result of an unsupervised learning process is an identifier that assigns a data record to a cluster.
The diagram and steps below illustrate an unsupervised learning application for segmenting customers.
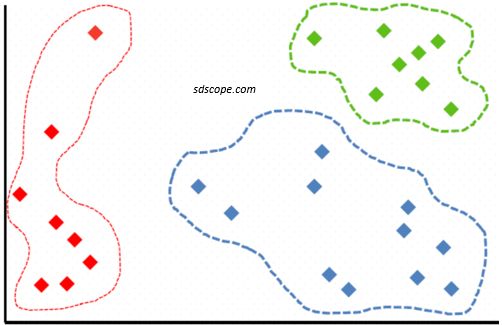
Step 1. Data that does not have labels is fed (eg., contains features of houses with no selling prices) into an unsupervised learning algorithm
Step 2. The algorithm finds patterns in the data on its own and outputs groupings
Step 3. To assign new records to a cluster either rerun the unsupervised algorithm or let the algorithm calculate the distance between the new record and the center of each existing cluster then assign the record to the nearest cluster



