
Model evaluation is the process of determining the capacity of a model to make useful predictions on new, never-before-seen data. The key approaches are outlined below.
Hold-out Validation #
Also known as split validation or train/test, the basic approach involves splitting a dataset into two partitions – a train set and a test set – to evaluate the performance of a model,. Sometimes a third portion, the validation set, is included for tuning certain features of a model. See illustration in Figure 1 below.
There are no established recommendations for partition ratios; the ratio depends mainly on size of dataset. Typical ratios are 80:20 or 70:30 for train:test split and 50:20:30 or 60:20:20 for training:validation:test split.

Train set, sometimes referred to as training set, is typically the largest partition. It contains the data used to find the basic model.
Validation set is used to tune the model as part of the process of building the model. It is used when there is enough data.
Test set, sometimes called the hold-out set, acts as a proxy for new data and is used to assess the performance of the model on new data.
Advantage
– Very fast, making it ideal for large datasets
Disadvantages
– Requires enough data to make suitably large partitions for the algorithms to learn and to test scenarios
– Susceptible to “lucky split” that places more hard-to-model instances in the train set and more easy-to-model instances in the test set, i.e., requires the dataset to be homogeneous
k-fold Cross Validation #
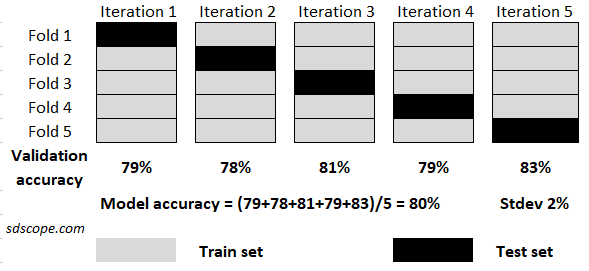
This approach is generally regarded as the gold standard for evaluating the performance of a model on unseen data. The process involves dividing a dataset into k equal-sized portions known as folds and using data in one fold as the test set while using the rest as the train set in turns until each fold is used as the test set exactly once. Figure 2 illustrates k-fold cross validation for k=5. The performance results of the runs are averaged to give the final model performance and the standard deviation of the performance measure.
The number of folds depends on the size of the dataset and computational resources available; typical values are 10, 5 and 3.
Advantages
– Less susceptible to variance because it uses the entire dataset
– Standard deviation information provides more insight for model selection
– Suitable for small datasets
Disadvantage
– Dramatically increases training time (~ multiplies by the number of folds), making it less suitable for large datasets
Leave One Out Cross Validation #
Also known as jackknifing, it is a special form of k-fold cross validation in which each fold of the test set contains only one instance and the train set contains the remainder. This is useful when the dataset is too small to perform meaningful k-fold cross validation.
Repeated Random Train/Test Split #
A variation of k-fold cross validation in which the dataset is randomly splits into a train set and a test set in a given proportion and the split/evaluation process performed for a specific number of times. It provides a balance between variance in the estimated performance, model training speed and size of dataset.
Advantage
– Combines the speed of hold-out validation and the ability of k-fold cross fold validation to minimize variance in performance
Disadvantage
– Susceptible to redundancy as the train set or test set may take a few of the same instances in each iteration during a run



